Abstract
A key challenge in building generalist agents is enabling them to perform multiple tasks while simultaneously adapting to variations across the tasks efficiently, particularly in a zero-shot manner. Multi-task Reinforcement Learning (MTRL) is a paradigm that enables agents to learn a single policy that can be deployed to perform multiple tasks in a given environment. A straightforward approach like parameter sharing introduces challenges such as conflicting gradients and determining the optimal way to distribute shared parameters across tasks. In this work, we introduce AMT-Hyp, a framework for training hypernetworks in MTRL that consists of HypLa- tent, an adversarial autoencoder that generates diverse task- conditioned latent policy parameters, and HypFormer, a single- layer transformer that performs soft-weighted aggregation on these priors towards expert policy parameters. Our approach not only outperforms previous hypernetwork based methods but also performs comparably to the existing state-of-the-art methods in MTRL on MetaWorld benchmark. Additionally, experiments on MuJoCo continuous control tasks demonstrate the frameworks strong zero-shot learning capabilities, allowing it to generalize to unseen in-distribution tasks without addi- tional fine-tuning. Our framework also achieves performance comparable to state-of-the-art offline meta-RL methods.
Overview
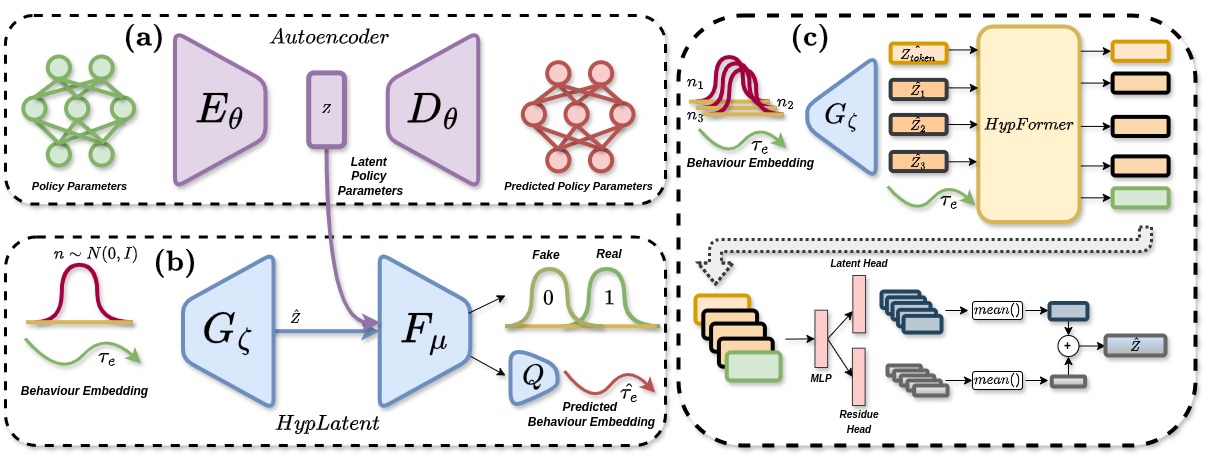
Architecture. consists of HypLatent, an adversarial autoencoder that generates diverse task- conditioned latent policy parameters, and HypFormer, a single layer transformer that performs soft-weighted aggregation on these priors towards expert policy parameters.